windows上powershell获取登录日志
# 获取从9月到现在的登录事件日志 $loginEvents = Get-EventLog -LogName Security -Inst...
openEuler release 23.09 换yum源
openEuler release 23.09[OS] name=OS baseurl=http://repo.huaweicloud.com/openeuler/openEuler-23.09/...
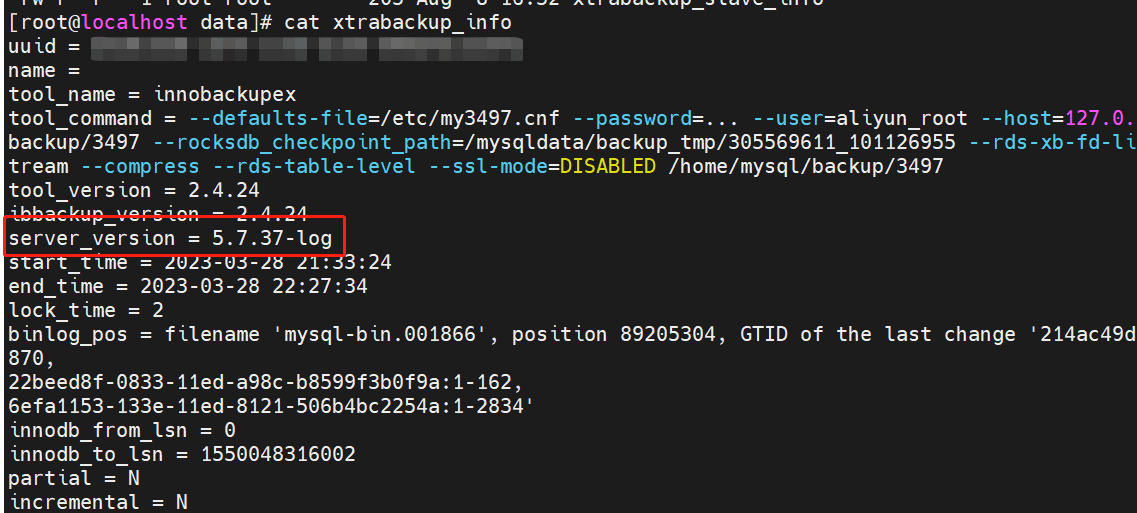

python使用ip2Region库离线查询ip地址归属地,生成Excel报告
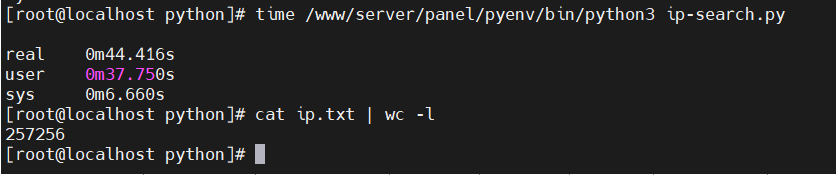
参考:python使用ip2Region库查询ip地址归属地查询/ip朔源自动生成Excel报告https://www.pythonheidong.com/blog/article/895015/58...